
그냥 게임개발자
unique() 본문
배열 중에서 아래와 같은 배열이 있다.
[1, 1, 2, 2, 3, 3]
그럼 이 중에서 중복된 것들을 삭제하는 것은 어떻게 할까?
첫번째 방법은 map이다.
간단하게 map을 사용해서 할 수 있다.
map에 1이라는 key를 넣고 value를 할당한다.
그러면 다음 1은 continue 할수가 있고 이런 식으로 하나의 map에 중복된 것들을 삭제하고 오름차순으로 나열 할 수 있다.
그럼 코드로 한 번 확인해보자.
#include <iostream>
#include <vector>
#include <map>
using namespace std;
map<int, int> mp;
int main()
{
vector<int> v{1, 1, 2, 2, 3, 3};
for (int i : v)
{
if (mp[i])
continue;
else
mp[i] = 1;
}
vector<int> ret;
for(auto it : mp)
{
ret.push_back(it.first); // first는 key이다.
}
for(int i : ret)
cout << i << '\n';
}

결과가 잘 나온 것을 확인할 수 있다.
두번째 방법은 unique다
unique는 범위 안에 있는 요소 중 앞에서부터 서로를 비교해가며 중복되는 요소를 제거,
그리고 나머지 요소들을 삭제하지 않고 그대로 두는 함수이다.
O(n)의 시간 복잡도를 가진다.
이제 unique를 사용한 코드를 살펴보자.
#include <iostream>
#include <algorithm>
#include <vector>
vector<int> v {2, 2, 1, 1, 2, 2, 3, 3, 5, 6, 7, 8, 9};
int main()
{
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());
for (int i : v)
cout << i << " ";
return 0;
}
여기서 보면 우리가 원하는 결과값은 [1, 2, 3, 5, 6, 7, 8, 9]이다.
중복된 것들은 삭제하고 오름차순으로 나열하기.
그렇다면 일단 여기서 문제점은 정렬을 안하고 unique를 사용하게 되면 결과값은 이렇게 나온다.
[2, 1, 2, 3, 5, 6, 7, 8, 9]
unique라는 것은 그림을 보면 이런 식으로 삭제한다.
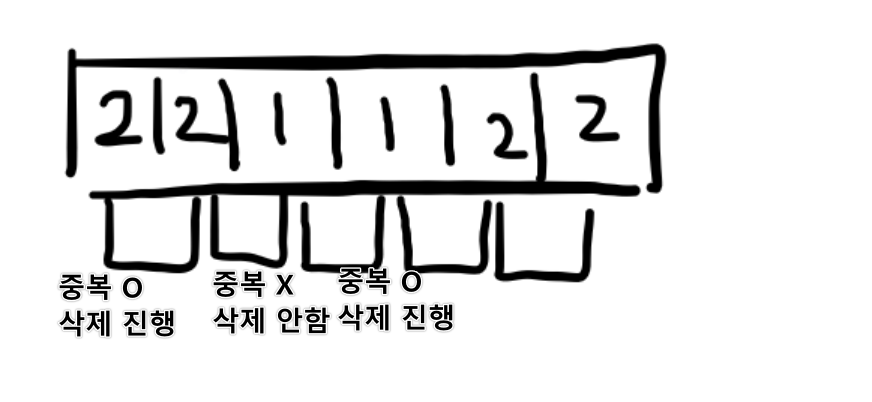
첫번째 인덱스부터 시작해 중복을 비교한다.
이 때 중복이다면 삭제하고 다음것을 비교합니다.
그러면 2와 1을 서로 검사하게 되는데 중복이 아니니 삭제를 진행하지 않는다.
그렇기에 [2, 1, 2, 3, 5, 6, 7, 8, 9]라는 결과가 나온 것이다.
전체를 검사한다는 것은 포괄적으로 생각하면 맞지만
실제 검사는 하나 하나 씩 검사하기 때문이다.
그렇기에 다시 코드를 보자면
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());
먼저 정렬을 진행한 후에 unique를 진행하는데
unique를 진행하게 되면 중복된 것을 삭제하고 그에 맞는 값을 넣어주는데 이게 다 끝나면 중복 삭제하고 삽입된 값들의 마지막 다음 인덱스를 반환한다.
이게 무슨 말이냐면
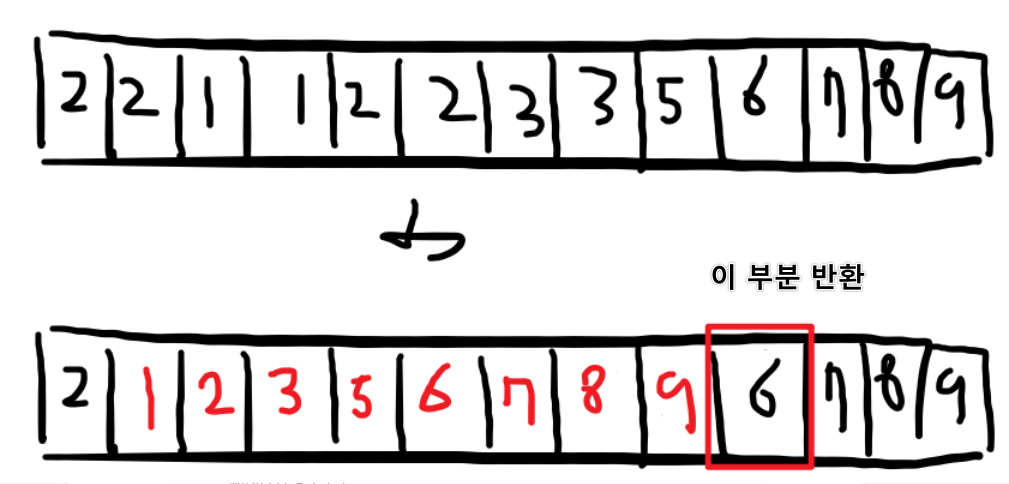
이런 식이다.
정렬된 것 삭제하고 값을 바꾼 뒤에 중복된 것들을 다 삭제하고 마지막 부분을 반환한다
그래서
v.erase(unique(v.begin(), v.end()), v.end());이런식으로 삭제를 해야한다.
erase는 from - to (어디서부터 ~ 어디까지) 삭제한다.
라는 뜻이다.
오늘은 여기까지
'C++ 나만의 복습' 카테고리의 다른 글
| 프로세스 메모리 구조와 정적할당과 동적할당 (0) | 2024.04.07 |
|---|---|
| 문자를 숫자로, 숫자를 문자로 (0) | 2024.04.07 |
| 역참조 연산자 (0) | 2024.04.05 |
| 포인터 (1) | 2024.04.05 |
| auto 타입 (0) | 2024.04.04 |



